
I’m glad we clarified this.
[Table from an MSc dissertation of an unnamed student.]
Data, tech, non-alc.
I’m glad we clarified this.
[Table from an MSc dissertation of an unnamed student.]

Here’s a confession: I am a carbon pig. Thanks to my travels, my carbon foot print this year is probably the size of a small Eastern European country. I am not happy with this, but I just can’t help the fact that a) travelling home to see my parents in Germany would take days by train, and b) flights are just so much cheaper than train fares. Anyway. This year, I have been extra busy with various conferences around Europe, which meant a) a lot of work, but also b) I got to see some amazing places! As my life in Manchester is currently restricted to writing a thesis, I’m going to post an n-part series (for n somewhere in the interval between 3 and 8) of my “European Travels”. Sit back and enjoy.

This year’s first trip took me to Berlin, to see some friends I hadn’t seen in over a year. We all know that Berlin is awesome, and I’ve written a 2-part post about it before, so I’ll just tell you about my trip to Potsdam this time. Potsdam is a small(ish) city just south-west of Berlin, about a 20-30 minute train journey from the main station. It’s a student town, but in German that’s usually a good thing, meaning green, loads of cyclists, culture, and hippie-ish people/places. Suits me. Potsdam is also known for various castles and lakes surrounding the town, including the very famous “Sanssouci” palace, which used to be the summer residence of the King of Prussia. I went to visit the town and Sanssouci on a rainy day, but despite some heavy showers I couldn’t help but spend quite some time in vast gardens surrounding the castle.
The palace itself (accessible via guided tour only) is nice, but… well, I’ve seen a lot of castles, and they all begin to look the same at some point. The gardens (free admission) and various little buildings (such as the “Dragon House” in the photo above) are definitely worth a visit though, and you should save some time to have a wander around the lovely city centre of Potsdam.

It’s been a while since I’ve written about life with our new lagomorphic housemate, so, in the light of current events – I just had a “aww look how awesome he is” chat with his soon-to-be pet sitter Lucy from Furry Feet Petcare – here’s an update of how Das Rabbit* is doing.
Previously on mightaswell:
As you may know, Geth moved in with us about a year and a half ago – and despite my worries about him destroying the flat and topping himself in the process, he quickly settled and accepted us as the people who bring him his food. After a short while, however, he developed a mysterious sneeze – I wrote about the first few months and the sneeze in a two part post on Dave’s blog.
In the meantime…
A lot has happened since the first 168 days of rabbit. A lot, and not much at the same time. After 7 months of several different antibiotics, both oral and as injections, two (two!) sinus endoscopies (that is, sticking a camera up the rabbit’s nose), two culture & sensitivity tests to grow bacteria, and an x-ray to see whether he’s got anything stuck up his nose (he didn’t, but the x-ray image looked pretty awesome!), and an astronomical vet bill (PEOPLE! GET. PET. INSURANCE.) the sneeze is still there. As the rabbit seems otherwise fit and has a healthy appetite, i.e. eats like a farmer (“aww, just like his mum!”), I’ve given up on doing anything about it. Meh.
On a more pleasant note, Geth has been quite a clever bunny who has learned a few things over the past year or so: He can now do a couple of tricks (hop over my leg and “spin” around himself), he’s overcome his fear of heights and learned to hop down the stairs in our flat (which means the bedroom is no longer safe from him), in the same instance he also figured out how to get on top of the dining table in order to sample the offerings of our fruit bowl, and he now knows that if he wants attention he just needs to flip his toilet bowl upside down. Winner.
One of the other things Geth is very good at is sleeping. Snoozing. Napping. Dozing. Catching z’s. Resting his eyes. And he is very creative in his choices of sleeping places around the flat. Some of these places include:
The window sill.

The book shelf. (He kept kicking out the books, so I gave in and declared the shelf rabbit zone.)

A suitcase under the bed. He blends in perfectly with the black suitcase. Camouflage bunny.

In the middle of the kitchen floor. Posing like a mini lion.

Under the coffee table.

Under the dining table. One day, he just started sitting on one of the chairs, so I put a cushion on it. It’s an official bunny zone now, including the “oh no that’s Geth’s chair” warnings for visitors. Yeah. I know. I am that woman now.

On the rug. This picture was taken after a particularly exhausting session of “destroy the box and spread hay all over the floor”. It’s a hard knock life.

Under the sofa, preferably after I’ve dropped a Big Issue down there for maximum shredding pleasure. See the guilty look on his little face? Yeah, me neither.

That should be enough rabbity catch up for now – but I’m sure you know there will be more rabbit posts soon. On that note: I don’t exactly know when his birthday is, but according to my estimates it’s “some time in autumn”. So:
My dear bunny friend, I wish you all the best for your 3rd birthday, may you be happy and healthy for many more years to come.
* Also known as Gethin, Geth, rabbit, rabs, rabtastico, bun, bunbun, buntzzz, bunster, “the original bunster”, chubster, sweet cheeks, sweetheart, mini-dude, duderino, du-du-duh-dude, mini-donkey, squirrel, sausage, and “NO!!”.
This is the second in a series of blog posts on “interesting explanation/debugging papers I have found in the past few months and that I think are worth sharing”. I’m quite good with catchy titles!
Nikitina, N., Rudolph, S., Glimm, B.: Interactive ontology revision. J. Web Sem. 12: 118-130 (2012) [PDF]
This paper follows a semi-automated approach to ontology repair/revision, with a focus on factually incorrect statements rather than logical errors. In the ontology revision process, a domain experts inspects the set of ontology axioms, then decides whether the axiom is correct (should be accepted) or incorrect (axiom is rejected). Each decision thereby has consequences for other axioms, as they can be either automatically accepted (if they follow logically from the accepted axioms) or rejected (if they violate the accepted axioms). Rather than showing the axioms in random order, the proposed system determines the impact a decision has on the remainder of the axioms (using some ranking function), and gives higher priority to high impact items in order to minimize the number of decisions a user has to make in the revision process. This process is quite similar to Baris Sertkaya’s FCA-based ontology completion approach, which employs the same “accept/decline” strategy.
The authors also introduce “decision spaces”, a data structure which stores the results of reasoning over a set of axioms if an axiom is accepted or declined; using this auxiliary structure saves frequent invocation of a reasoner (83% of reasoner calls were avoided in the revision tool evaluation). Interestingly, this concept on its own would make for a good addition to OWL tools for users who have stated that they would like a kind of preview to “see what happens if they add, remove or modify an axiom” while avoiding expensive reasoning.

Conceptually, this approach is elegant, straightforward, and easily understandable for a user: See an axiom, make a yes/no decision, repeat, eventually obtain a “correct” ontology. In particular, I think it the key strengths are that 1) a human user makes decisions whether something is correct or not, 2) these decisions are as easy as possible (a simple yes/no), and 3) the tool (shown in the screenshot above) reduces workload (both in terms of “click count” as well as cognitive effort, see 2)) for the user. In order to debug unwanted entailments, e.g. unsatisfiable classes, the set of unwanted consequences can be initialised with those “errors”. The accept/decline decisions are then made in order to remove those axioms which lead to the unwanted entailments.
On the other hand, there are a few problems I see with using this method for debugging: First, the user has no control over which axioms to remove or modify in order to repair the unwanted entailments; in some way this is quite similar to automated repair strategies. Second, I don’t think there can be any way of the user actually understanding why an entailment holds as they don’t get to see the “full picture”, but only one axiom after another. And third, using the revision technique throughout the development process, starting with a small ontology, may be doable, but debugging large numbers of errors (for example after conversion from some other format into OWL or integrating some other ontology) seems quite tedious.
Via the @EKAW2012 Twitter account I just landed on the “conferences” list on semanticweb.org. Since 2007, the conference metadata of several web/semweb conferences (WWW, ISWC, ESWC…) has been published as linked data, including the accepted publications (with abstract, authors, keywords, etc) and list of invited authors. Check out the node for my ISWC 2011 paper, for example.
I’m quite tempted to experiment with this and generate some meta-meta-data. Do you know of any applications using these data, or have you got any ideas what to do with it?
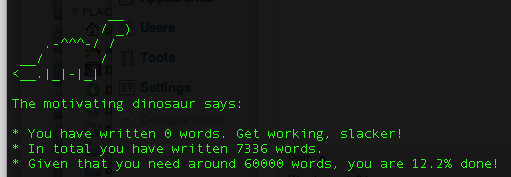
Two things that might be relevant for understanding what I did here:
Voila, the “LaTeX motivator” script is born (based on a version by my supervisor… but mine has special effects). Download it off github, copy the scripts (.py plus the .pl wordcount script) into the directory with your tex files, run latex-motivator.py, select your favourite motivating animal, and off you go. Now all you have to do is write a thesis. Easy!
Update: It seems that the stats.csv output is a bit broken. Will fix once I’ve written enough to make the dino happy.
After my excursion into the world of triple stores, I’m back with my core research topic, which is explanation for entailments of OWL ontologies for the purpose of ontology debugging and quality assurance. Justifications have been the most significant approach to OWL explanation in the past few years, and, as far as I can tell, the only approach that was actually implemented and used in OWL tools. The main focus of research surrounding justifications has been on improving the performance of computing all justifications for a given entailment, while the question of “what happens after the justifications have been computed” seems to have been neglected, bar Matthew Horridge’s extensive work on laconic and precise justifications, justification-oriented proofs, and later the experiments on the cognitive complexity of justifications. Having said that, in the past few months I have come across a handful of papers which cover some interesting new(ish) approaches to debugging and repair of OWL entailments. As a memory aid for myself and as a summary for the interested but time-pressed reader, I’m going to review some of these papers in the next few posts, starting with:
Shchekotykhin, K., Friedrich, G., Fleiss, P., Rodler, P.: Direct computation of diagnoses for ontology debugging. arXiv 1–16 (2012) [PDF]
The approach presented in this paper is directly related to justifications, but rather than computing the set of justifications for an entailments which is then repaired by repairing or modifying a minimal hitting set of those justifications, the diagnoses (i.e. minimal hitting sets) are computed directly. The authors argue that justification-based debugging is feasible for small numbers of conflicts in an ontology, whereas large numbers of conflicts and potentially diagnoses pose a computational challenge. The problem description is quite obvious: For a given set of justifications, there can be multiple minimal hitting sets, which means that the ontology developer has to make a decision which set to choose in order to obtain a good repair.
Minor digression: What is a “good” repair?
“Good repair” is an interesting topic anyway. Just to clarify the terminology, by repair for a set of entailments E we mean a subset R of an ontology O s.t. the entailments in E do not hold in O R; this set R has to be a hitting set of the set of all justifications for E. Most work on justifications generally assumes that a minimal repair, i.e. a minimal number of axioms, is a desirable repair; such a repair would involve high power axioms, i.e. axioms which occur in a large number of justifications for the given entailment or set of entailments. Some also consider the impact of a repair, i.e. the number of relevant entailments not in E that get lost when modifying or removing the axioms in the repair; a good repair then has to strike a balance between minimal size and minimal impact.
Having said that, we can certainly think of a situation where a set of justifications share a single axiom, i.e. they have a hitting set of size 1, while the actual “errors” are caused by other “incorrect” axioms within the justifications. Of course, removing this one axiom would be a minimal repair (and potentially also minimal impact), but the actual incorrect axioms would still be in the ontology – worse even, the correct ones would have been removed instead. The minimality of a repair matters as far as users are concerned, as they should only have to inspect as few axioms as possible, yet, as we have just seen, user effort might have to be increased in order to find a repair which preserves content, which seems to have higher priority (although I like to refer to the anecdotal evidence of users “ripping out” parts of an ontology in order to remove errors, and some expert systems literature which says that users prefer an “acceptable, but quick” solution over an ideal one!). Metrics such as cardinality and impact can only be guidelines, while the final decision as to what is correct and incorrect wrt the domain knowledge has to be made by a user. Thus, we can say that a “good” repair is a repair which preserves as much wanted information as possible while removing all unwanted information, but at the same time requiring as little user effort (i.e. axioms to inspect) as possible. One strategy for finding such a repair while taking into account other wanted and unwanted entailments would be diagnoses discrimination, which is described below.
Now, back to the paper.
In addition to the ontology axioms and the computed conflicts, the user also specifies a background knowledge (those axioms which are guaranteed to be correct), and sets of positive (P) and negative (N) test cases, such that the resulting ontology O entails all axioms in P and does not entail the axioms in N (an “error” in O is either incoherence/inconsistency, or entailment of an arbitrary axiom in N, i.e. the approach is not restricted to logical errors). Diagnoses discrimination (dd) makes use of the fact that different repairs can have different effects on an ontology, i.e. removing repair R1 and R2 would lead to O1 and O2, respectively, which may have different entailments. A dd strategy would be to ask a user whether the different entailments* of O1 and O2 are wanted or unwanted, which leads to the entailments being added to the set P or N. Based on whether the entailments of O1 or O2 are considered wanted, repair R1 or R2 can be applied.
With this in mind, the debugging framework uses an algorithm to directly compute minimal diagnoses rather than the justifications (conflict sets). The resulting debugging strategy leads to a set of diagnoses which do not differ wrt the entailments in the respective repaired ontologies, which are then presented to the user. When taking into account the set of wanted and unwanted entailments P and N, rather than just presenting a diagnosis without context, this approach seems fairly appealing for interactive ontology debugging, in particular given the improved performance compared to justification-based approaches. On the other hand, while justifications require more “effort” in comparison than being presented directly with a diagnosis, they also give a deeper insight into the structure of an ontology. In my work on the “justificatory structure” of ontologies, I have found that there exist relationships between justifications (e.g. overlaps of size >1, structural similarity) which add an additional layer of information to an ontology. We can say that they not only help repairing an ontology, but also potentially support the user’s understanding of it (which, in turn, might lead to more competence and confidence in the debugging process).
* I presume this is always based on some specification for a finite entailment set here, e.g. atomic subsumptions.
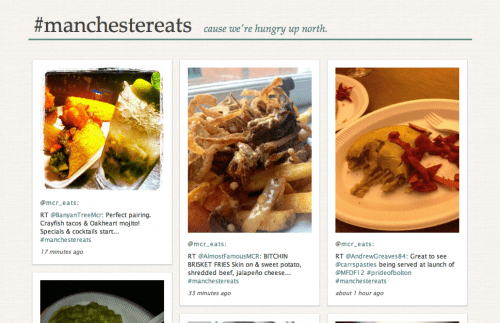
So, you know I do computery stuff for a day job.* And I genuinely enjoy doing computery stuff in my spare time, too. Long story short: I played with the Twitter API and jQuery and out came manchestereats.com – a site which does what you all love: Show pretty pictures of tasty food. Think Pinterest for food in Manchester. A very specific Pinterest. Some might even call it pointless. Oh, whatever. Go on the Twitters, tweet your breakfast/lunch/dinner/snacks with the hashtag #manchestereats (or #mcreats if you prefer it shorter), then go and drool over manchestereats.com.
* Job = I get EPSRC money for writing hundreds of pages of text which no more than 3 people (examiner 1, examiner 2, and both supervisors to an approximated 50%) in the world will ever read, but hey ho.

Taken at 1847′s new restaurant in Chorlton. Lovely place, let’s not talk about the food.
So, I got caught up in a torrential rain storm on my way home last night, and, having screamed at the rain all the way while cycling down Oxford Road, I did the only reasonable thing and sought shelter at Big Hands. As I was trying to get a little dryer (by sitting on bench… I know, good story, right?) I started chatting to some Australian girls who had been in Manchester for a few weeks. I kept asking which places they had been to and ended up jotting down a list of my favourite spots to visit in Manchester. I couldn’t help but turn this into a blog post,* so there you go:

Museum of Science and Industry (MOSI)
Oh, how I love this place. Whether it’s for a full tour round the different exhibitions (which can easily take you half a day), or just for a sneaky visit to the absolutely magnificent steam engine hall, MOSI is one of my staples to take visitors to. If you’re lucky, the steam engines are running, and you can spend quite some time just marvelling at these fantastic pieces of engineering, with their bolts and pistons moving to what seems like a perfectly choreographed little dance. Well, I do.
The Knott
This pub, just round the corner from MOSI, offers some of the tastiest pub grub in town. They used to have a grilled halloumi sandwich which was so good, it made me weep (I do get very emotional when eating nice veggie food); the Lancashire cheese and beet root pie (if that’s your kind of thing), however, has now become my new favourite.
Cloud 23
While I find Cloud 23 as a bar rather unattractive, it’s definitely worth a visit for the Afternoon Tea (or, aptly named, “High Tea”). Watch Manchester from above while eating cake – winner.

Affleck’s Palace
It seems every Mancunian has a story of how they used to hang out at Affleck’s in their teens. This indie shopping mall is a huge maze of little shops spanning several floors, ranging from second hand to fancy dress, posters and badges, hand-made jewellery, and general weird stuff. There’s a tasty little milk shake bar hidden in some corner on the 1st floor (maybe… I tend to lose my bearings as soon as I enter the building), a cafe on the top floor, and endless hours of fun.
The Star & Garter
When I first moved to Manchester, I spent many a Saturday night dancing at Smile, “Manchester’s longest running indie night” at the Star&Garter pub. While the novelty of drinking double g&ts and falling up and down the epic staircase has worn off, I still enjoy the odd night out at Smile, dancing to some excellent and un-embarrassing tunes. I’ve never made it to the Smiths night (which, apparently, attracts a fair number of quiffs), but it’s definitely on my “things to do before I leave Manchester” list.
Big Hands & The Temple
While I don’t usually spend too much time at pubs, Big Hands and The Temple are certainly two of my favourite places in Manchester. They’re gloriously dark and scruffy places with similarly scruffy patrons, brilliant jukeboxes (always fun to take non-Brits who are not yet used to the concept of jukeboxes) and overpriced beer.
The Cornerhouse
This art gallery/cafe/bar/restaurant/cinema “complex” is always a safe bet if you fancy art/coffee/drinks/food/indie and artsy movies. Having said that, the cosy little cinema screens are certainly my favourite, in particular because you’re ok to bring in your own snacks (unlike basically any other cinema). My go to combo for rainy days is a pack of biscuits and a cup of tea from the cafe to go with my movie.

Manchester Museum
I like to hang out in the live animals bit of Manchester Museum and watch the chameleon climbing around its little artificial rainforest, which is strangely meditative. Apart from that, it’s the place to go if you’re into dead animals (stuffed and skeletons alike). The bony dude on the picture is called Stan, by the way.
Fuel, Withington (south)
Fuel Fuel Fuel Fuel Fuel Fuel Fuel. I love Fuel. If it was legal to marry pubs, I’d have drunkenly proposed to Fuel a few times already. Mind you, I probably have. There’s veggie food, which always ends up being absolutely perfect, lovely staff, a brilliant quiz on Tuesdays (hosted by two Welsh brothers), open mic on Wednesdays, free gigs on weekends ranging from hip hop to hardcore and back, knitting groups, poetry, comedy, and what not. Oh and there’s no bouncer to yell at you when you stand outside with a drink, so on busy nights half of the fun is usually happening outside on the pavement.
Fletcher Moss Park, Didsbury (south)
My favourite park in Manchester. The Japanese garden is absolutely gorgeous in spring/summer.
Bury Market, Bury (north)
One of the biggest markets in Europe. Definitely worth the visit if you want to eat your way across the continents and perhaps buy some slippers.

Boggart Hole Clough, Blackley (north)
I came across this place very randomly when I got my first bike in Manchester and pointed at a map saying “let’s cycle to that place with the funny name“. This seemingly average park turns into what can only be described as a huge hole in the ground, with a little garden and a few benches at the bottom. We sat there eating our lunch while watching a small group in fancy dress filming what looked like an Alice in Wonderland themed scene. Weird-o-rama.
Islington Mill, Salford (north west)
There’s art, gigs, yoga, dancey nights, and more gigs. For some unknown reason, I hardly ever make it down that side of town, but if I weren’t such a lazy bugger, I’d definitely spend more time at the Mill. You should go. It’s good.
Now it’s your turn – What are your favourite (non-pub) places in Manchester?
* I actually woke up at 6am and couldn’t go back to sleep because I was so excited about the idea of writing this up as a blog post. And while getting out of bed to write is certainly laudable, not sleeping off the drinks has started to take its toll on me over the course of this blog post being written and I only just about managed to finish it without curling up on the sofa. I guess that’s what they call “writer’s dilemma”.
[Images cc-licensed by no22a, ScraggyDog, marcus_and_sue, and Pimlico Badger because I lost 30GB worth of photos in a Time Machine backup accident.]

You must be logged in to post a comment.